[youtube] PR-175: XLNet: Generalized Autoregressive Pretraining for Language Understanding : https://www.youtube.com/watch?v=koj9BKiu1rU 참고
Abstract

이전의 Transformer XL 과 똑같은 저자분들이 등장함 (reject)
Pretraining model 을 크게 두개로 나누어서 설명하고 있음
- Autoregressive
yt = ayt-1 - ut
Y 는 현시점 Y 에 영향을 주는 자기 자신에 대한 함수가 됨 (forward, backward 가 존재)
(한방향으로 가기 시작하면 그 다른 정보는 볼 수 없다는 단점이 존재 bidirectional rnn 결과도 forward 따로 backward 따로였기 때문에
진정한 의미의 bidirection 은 아니었음 (text generation 시에 기존의 token 을 가지고 다음을 예측하는 것과 잘 맞기 때문에 좋은 성능을 내고 있음))
이 모형을 특별히 1st order autoregressive model 이라고 함
input seq = x = (x1, x2, ..., xT) 로 가정하면 likelihood 의 값이 곱의 형태로 나오게 됨 (독립이라는 가정이 존재)
기존 확률들의 누적으로 현재의 형태가 표현되는 구조임
목적함수로는 로그 확률로 각각이 더해지는 형태로 구성할 수 있음
- Autoencoding
AE 는 주어진 input 에 대해 모델을 통과한 값이 원래 input 을 그대로 예측하는 문제를 풀어감
(전체 seq 를 가지고 일부를 masking 을 하고 token 이 실제로 어떤 것이었는지 맞추는 방식)
Denoising AE 의 경우 noise 가 섞인 input 을 원래의 input 으로 예측하는 문제를 품
BERT 의 경우 input seq 에 대해 각 mask 의 정답 token 이 등장할 확률은 독립이 아니지만 각 확률의 곱을 나타내기 위해 독립이라고 가정함
그래서 애매하게 같다는 등호를 사용
기존 BERT 의 문제
- BERT : bidirectional contexts, denoIsing autoencoding based pretraining
- BERT 가 autoregressive LM 보다 훨씬 성능이 좋았음
- BERT 는 masked positions 와 pretrain-finetune 시의 불일치 문제가 있음
XLNET 이 제안하는 바
- 전체에 대한 예상 likelihood 를 최대화하여 bidirectional contexts 를 학습함
- 자기 회귀 공식을 통해 BERT 의 한계를 극복
- masked token 사이에 있는 값들은 제대로 담아내지 못함
- 아래 공식과 같이 NEW 가 나오고 YORK 이 곱해질 확률과 YORK 이 나오고 NEW 가 곱해질 확률은 달라야하는데 가정을 independent 하다고 하였기 때문에 둘의 확률이 같게 나옴
- XLNET 은 Transformer-XL 에서 착안된 아이디어로 pretraining 에서 sota 를 달성하였음
- XLNET이 BERT 의 task 중 20 개를 뛰어넘음
1. Introduction
- AR 과 AE LM 은 가장 뛰어난 pretraining objectives 들임
Auto Regressive Language modeling
- auto regressive model 을 통해 text corpus 의 확률 분포를 추정함
- AR language modeling 은 조건부 분포에 의해 학습됨
- AR Language model 은 uni-directional 한 모델을 학습시키기 위해 사용되었음
- language understanding task 의 경우 bidirectional context information 이 필요함
Likelihood 와 Objective (AR 세부 설명)
- input seq 의 likelihood 는 forward backward 방향의 conditional probability 들의 곱으로 나타냄
- 모델은 이러한 conditional distribution 을 objective 로 학습함 (negative-log likelihood)
- AR 은 forward, backward 에 대한 방향이 정해져야 함
- 한쪽 방향의 정보만을 이용할 수 있음 (ELMo 의 경우 양방향을 이용하지만 각 방향에 대해 독립적으로 학습된 모델을 이용하므로 얕은 이해만 가능함)
Auto Encoder Language modeling
- AE 기반 사전 훈련은 명시적으로 density estimation 을 수행하지 않음
- denoising 된 입력에서 원본 데이터를 재구성하는 것을 목표로 함
- input token 이 주어지면 랜덤한 부분의 token 들이 [MASK] 토큰으로 대체됨
- model 은 원래 token 을 복원하도록 훈련 됨
- BERT 는 density estimation 의 목표와 어긋남 (BERT는 bidirectional contexts 를 재구성 함)
Denoising Auto Encoder
- input 그대로 예측하는 문제를 풀고 noise 가 섞인 input 을 원래의 input 으로 예측하는 문제를 품
- noise token 이 주어졌을 때 [mask] 토큰을 원래 input 으로 복구하고자 함
- p(x- | x^) 와 이를 Maximize 하는 objective 를 이용함
- 이것을 계산하는 과정에서 차이점이 존재
- independent assumption
- 주어진 input seq 에 대해 각 [MASK] token 의 정답 token 이 등장할 확률은 독립이 아니지만 독립으로 가정
- 독립으로 가정하면 확률의 곱으로 표현할 수 있음
- xt 가 [MASK] token 일 경우 mt = 1, 나머지 경우에는 mt = 0 mask 토큰에 대해서만 prediction 을 진행함
- mt 를 둬서 [mask] token 만 예측하는 objective 는 denoising autoencoder 의 objective (input + noise 에 대해 input 을 복원 noise 의 위치와 관계없이 input 전체를 복원)
- noise 자체는 실제 fine-tuning 과정에는 등장하지 않으므로 pre-training 과 fine-tuning 사이의 불일치가 발생
- 모든 token 이 독립적으로 예측되어 이들 사이의 dependency 학습 불가능
Pros Cons
- AE 를 사용하면서 얻을 수 있는 장점은 AR 언어 모델링에서 앞서 언급한 bidirectional information 격차를 해결할 수 있다는 것
- BERT 에 의해 사용된 MASK 는 finetuning 시 사용되지 않음 (pretrain-finetune 불일치 문제 발생)
- BERT 는 AR language modeling 에서 사용한것 처럼 joint probability 를 사용할 수는 없음
- BERT 는 각각의 unmasked tokens 들에 대해 tokens 를 독립적으로 예측됨
- high-order, long-range dependency 가 지나치게 단순화됨
XLNET 의 제안
- 앞서 언급했던 두가지 AR, AE 모두의 장점을 최대한 활용하면서 한계를 피하는 일반화된 자동회귀 방법

- 새로운 Objective 를 제안
- AR model 의 forward, backward factorization 을 수정
- XLNet 은 seq 의 log likelihood 를 극대화
- 모든 factorization order 의 permutations 가 가능해짐
- Permutation operation 에 의해 left / right 의 모든 position 을 가질 수 있게 됨 (capturing bidirectional context)
- 일반적인 AR LM 에서 XLNet 은 data corruption 에 의존하지 않음
- XLNET 은 pretrain-finetune discrepancy 를 겪지 않음
- autoregressive model 은 예측 token 에 대해 joint probability 를 사용하므로 BERT 의 예측의 독립성을 제거한다.
- novel pretraining objectives 에 대해서 XLNet 은 pretraining architectural designs 를 개선시킴
- AR Language modeling 에 착안하여 XLNet은 Transformer-XL의 세그먼트 반복 메커니즘과 인코딩 체계를 사전 훈련에 통합함
더 긴 텍스트 시퀀스와 관련된 작업의 성능 향상을 실험적으로 확인하였음 - 단순히 Trasformer architecture 를 permutation-based lM 에 적용하였을 때 정상적으로 동작하지 않음
- factorization 의 순서가 임의적이며 대상이 모호함
- ambiguity 를 지우기 위해 Transformer network 를 reparameterize 함
Related Work




- permutation 기반 AR modeling 아이디어는 32번 12번에서 탐구되었음
- 순서가 없는 귀납적인 bias 를 적용하여 density estimation 을 개선하는 것을 목표로함
- XLNet 은 AR 언어 모델이 양방향 컨텍스트를 학습할 수 있도록 하여 동작하게 함
- target 을 예측하기 위해 XLNet 은 2 stream 을 통해 target position 을 hidden state attention 으로 통합함
- 이전 permutation AR model 은 고유한 position awareness 에 의존하였음
- NADE 와 XLNet 모두 순서가 없음이 seq 가 무작위 permutation 으로 구성될 수 있음을 의미하는 것이 아닌 모델이 분포의 다른 factorization 의 차수를 활용한다는 것을 의미함
- XLNet 에서는 고정된 순서만 고려하는 text generation된 context 에서 autoregressive denoising 을 수행함
2. Proposed Method: XLNet
2-1. Background


- 일반적인 AR 의 objective function h(seta)(x1:t-1) 은 model 의 context representation임 (RNN, Transformers 와 동일)
- e(x') 는 x 의 embedding 이다.
- BERT 는 x^ 이 random 하게 setting 되었다.
- x- 은 mask 된 token 을 말한다
- training objective 는 x- 을 x^ 을 통해 복원하는 것이다.
- XLNet 은 AR 과 AE 를 아래 3가지 관점에서 비교하여 각각의 장점만 취득함
- Independence Assumption
AE 의 objective function 은 조건부 확률을 계산하는 것임 모든 x- 에 대해 reconstruction 이 independent 하게 이루어진다는 가정하에 이루어짐.
반면 AR 의 objective function 은 이러한 가정이 없이도 성립함. - Input noise
AE 에서는 [Mask] token 과 같이 실제 input 에 없던 token 들이 추가되게 됨
pretraining 때에만 존재하는 token 으로 fine-tuning 과정에서는 존재하지 않음
이러한 pretraining 과 fine-tuning 사이의 괴리를 해결하기 위해 BERT 에서는 masking에 대해 모두 [mask] 로 처리하지 않고 orginal 을 그대로 두는 등의 방법을 사용했으나 의미 있는 결과를 도출할 수 없었음
AR 에서는 input 에 대한 변경이 없기 때문에 이러한 문제가 발생하지 않음 - Context dependency
AE 는 bidirectional context 를 모두 학습할 수 있지만 AR 은 undirectional context 만 학습함
- Independence Assumption
2-2. Permutation Language Modeling Objective

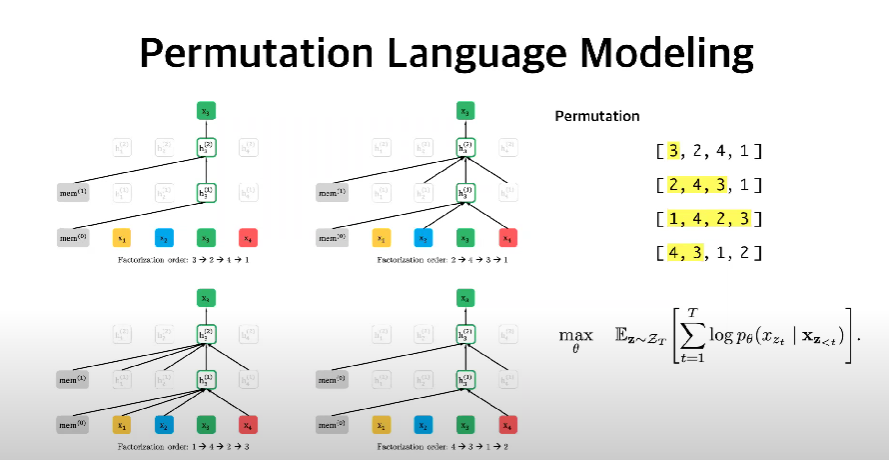
- AR 의 장점은 모두 취하면서 AR 의 단점을 해결하는 (Bidirectional Context) Objective Function 을 정의하기로 함
- ZT 는 길이가 T 인 seq 의 모든 순열 집합을 뜻함
- Zt 는 ZT 에서 t 번째 element 를 의미함
- Z<t 는 ZT 에서 0~t-1 번째 원소들을 의미함
- Objective function 은 xi 에 대해 xi 를 제외한 모든 xt 를 전체 집합으로 하는 순열에 대해 likelihood 를 구하게 됨
- AR 의 구조를 채택했으나 permutation 을 사용해 bidirectional context 까지 학습하도록 한 것

Permutation 은 input 이 될 때에 조합을 섞어놓고 학습을 진행한다.
8개의 seq 가 있다면 가능한 조합은 8! 가 됨
Forward 와 Backward 둘다 조합에 들어가게 됨
x3 을 예측한다고 하였을 때
3이 제일 처음에 나와있는 값이므로 해당 값을 관심값으로 setting 함 3은 제일 처음에 있는 값이므로 이전의 정보를 들고오지 않음
왼쪽의 회색 박스는 이전 정보를 저장해둔 memory 같은것이라고 이해
두번째 리스트의 경우 3의 이전에 2 4 가 있으므로 해당 값을 가짐
이렇게 계속 반복된다
permutation 은 계산을 조합한 뒤에 앞에 값들을 가지고 뒤에 값을 예측하게 됨 (auto regressive 함)
permutation lm 은 is a city 를 통해 new 를 예측하고 또 다시 new 까지 합친 것에서 York 를 예측한다.
이렇게 수행하면 치명적인 단점이 존재하게 됨
2-3. Architecture: Two-Stream Self-Attention for Target-Aware Representations

permutation LM 은 input token 들이 이렇게 섞은 뒤에 판단하므로 다음에 나올 token 이 어느 위치에 있는 token 일지 알 수가 없음
2134 를 가지고 판단해야한다고 가정하면 조합의 순서에 따라 5일 수도 있고 6일수도 7일 수도 있게 된다.
이 정보를 사전에 입력할 수가 없음
이것을 해결하기 위해 Two-stream self-attention 을 사용
2가지의 self attention 을 사용함

- 일반적인 Transformer 의 Self-Attention 구조에서는 Q, K, V 가 모두 같은 값으로 시작되게 됨
- 하나의 hidden state 의 값을 공유함 XLNet 에서는 구조상 Query, Key, Value 가 모두 같은 값으로 시작됨
- XLNet 에서는 구조상 Query 의 값과 Key, Value 의 갓이 분리되어야 한다.
- Z1 에서 T = 4 일 때 두가지 순열이 결정되었다고 가정하면 t = 3 에 대한 조건부 확률을 구하고
- Z2 에서 T = 3 에 대한 조건부 확률을 구하게 된다.
- 위의 두 조건부확률식은 완전히 같은 식임. x1 가 x4 가 같은 word 라면 완전히 같은 조건부 확률을 계산하는 상황이 발생함
- 직전 시점 t-1 까지의 정보 embedding 을 저장하는 representation 만으로는 이러한 문제를 해결할 수 없음.
- 현재 시점위 위치정보까지 받는 새로운 representation g 를 추가함
Content Representation
h seta 는 기존 Transformer 의 hidden state 와 동일한 구조임
현재 시점 (t) 의 정보까지 포함해 입력으로 받음 -> Content Representation 이라고 하고 Key, Value 에 사용
g 는 현재 시점 t 의 정보를 제외하고 입력으로 받음
대신 현재시점의 위치정보는 입력으로 받음 (Query Representation)
Permutation Language Modeling with Two Stream Attention
Query 의 초기값은 wieght key value 의 embedding 된 input 값 e임.
이후 Query Stream 은 현재 시점 t 의 위치정보는 알 수 있지만 실제 xz 는 알지 못하는 상태로 구해짐
Content Stream 은 현재 시점 t 의 위치정보는 물론 실제 값도 사용해 구해짐
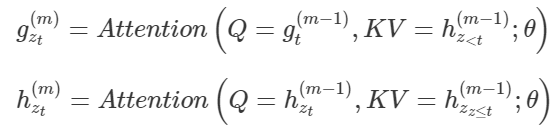
기존의 selft attention 과 다르게 두개를 사용 Query 와 Content 를 사용 Content stream 은 예측하고자 하는 token 을 같이 학습함
predict 해야할 정답 라벨을 같이 학습시킨다는것은 말이 안됨
그래서 Query stream 으로 함께 학습하게 됨
Query stream 은 전에 있는 정보들을 활용하되 마지막의 예측해야할 토큰에 대해 위치 토큰 임베딩만 가져와서 사용하게 됨
m 은 Multi-head Attention Layer 의 현재 Layer Number 임
세부 설명
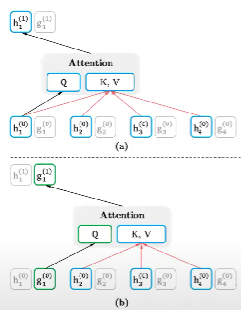
왼쪽 위 부분이 (self attention) standard transformer 임
Q K V 를 다 구해서 Q 를 weight sum 하게 되면
b 번을 확인해 보면 기존처럼 맨 처음에 토큰들을 가져오지 않고 이후 token 들을 가져오고 g1 에는 random initialize 값과 position 에 대한 정보만 가질 수 있도록 하는 attention 이 됨
masked two stream attention 이라고 함
- content 의 경우에 자기 자신을 볼 수 있고
- Query 의 경우에는 자기 자신을 볼 수 없음
2-4. Modeling Multiple Segments
해당 부분은 transformer-XL 에서 정의된 방식이다.
- segment recurrence
- 고정된 시퀀스가 있을 때 해당 sentence 에 대해서만 문장을 가져오는 것은 한계가 있음
- 실제 task 는 조금 더 긴 context 를 가져와야한다는 문제에서 나옴
- segment 를 쪼갠다음 이전 segment 를 다음 segment 로 이어져서 가져온다는 것
- new segment 가 들어왔을 때 fixed 에 대한 이전 정보를 cache 로 갖고 있다가 다음의 결과를 내는 것임
- BERT 의 Input 과 동일한 구조를 채택함
- [CLS, A, SEP, B, SEP] 의 구조임
- A 와 B 는 각각 sentence A, sentence B 이다.
- BERT 와의 차이점은 NSP 를 Pretraining 에 적용하지 않은 것 (BERT 에서 유의미한 성능 향상이 없었기 때문)
2-5. Relative Segment Encodings

- BERT 의 segment embeddings 는 Sa 와 Sb 등으로 A 문장인지 B 문장인지를 드러냈음
- XLNet 에서는 Transformer-XL 의 relative positional encoding 의 idea 를 segment 에도 적용해 relative 한 값으로 표현함
- XLNet 의 segment Encoding 은 두 position i, j 가 같은 segment 라면 다른 segment 라면으로 적용된다.
- 이러한 relative segment encoding 은 재귀적으로 segment encoding 을 찾아내면서 generalization 한 표현이 가능하다는 점 segment input 에 대한 처리 가능성을 열었다는 점에서 의의가 있음
2-6. Discussion
- 구체적인 예시를 들어 BERT 와 비교 "New York is a city" 라는 문장을 pretraining 하는 상황
- [New, York] 의 두 token 을 predict 하는 것이 목표임
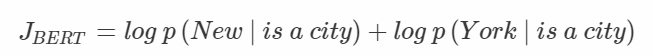
- XLNet 은 순열을 특정해야 objective 를 구체화 할 수 있음
- XLNet 은 AR Model 이므로 input sentence 에 변형을 가하지 않았고 predict target word 사이의 dependency 역시 학습할 수 있음
- 위의 예시에서는 York 를 예측할 때 New token 의 정보를 활용함

'NLP' 카테고리의 다른 글
| SpanBERT[Improving Pre-training by Representing and Predicting Spans] - 논문리뷰 (0) | 2022.08.01 |
|---|---|
| RoBERT [A Robustly Optimized BERT Pretraining Approach] - 논문리뷰 (0) | 2022.08.01 |
| GPT-2 - 논문리뷰 (0) | 2022.07.21 |
| BERT [Pre-training of Deep Bidirectional Transformers for Language Understanding] - 논문리뷰 (0) | 2022.07.11 |
| GPT-1 [Improving Language Understanding by Generative Pre-Training] - 논문리뷰 (0) | 2022.07.07 |