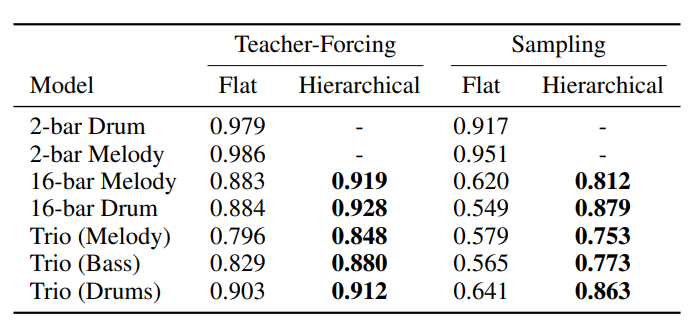
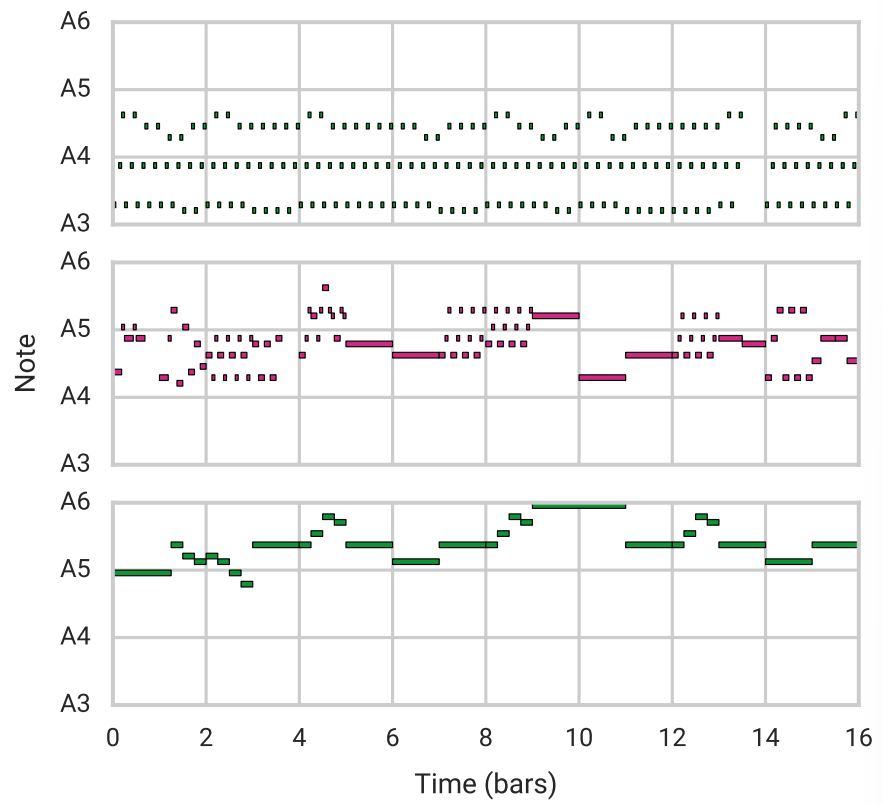
- music vae 논문 세미나 (다음주에 전체 코드와 함께 세밀하게 리뷰) vae 는 기본적으로 이미지에서 사용하던 task sequence 데이터 continuous 한 데이터에 적용하기엔 문제가 있었음 -> posterior collapse problem 이 문제를 해결하기 위해 encoder decoder 단에 lstm 의 사용 등의 아이디어를 생각하였지만 music vae 에서는 decoder 단에서 latent vector 의 범위를 제한 시켜 conductor 라는 하나의 계층을 추가하고 conductor 는 임베딩 벡터를 생성하게 됨 디코더는 자기 회귀적으로 분포를 생성 논문 이해 전에 vae 기본 구현과 cvae, b-vae 의 이해가 필요하겠다는 생각을 하였음 https://mpost..