1. Introduction
Generative 모델의 정의 : p(x) 분포에서 x 를 생성하기 위해 사용됨
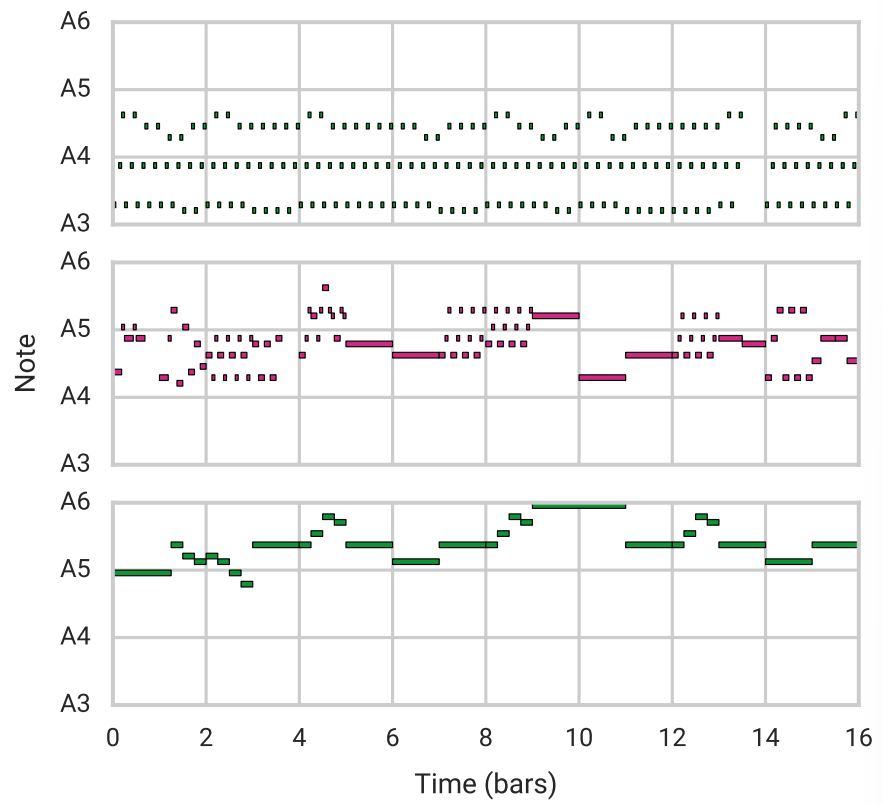
두가지 notes 를 interpolate 함
Gan 이나 Pixel CNN 과 Wave Net 같이 다양한 generative 모델이 있음
p(z|x) p(z) , z latent vector 가 존재하는 데이터로 부터 생성될 수도 있고 latent space 로 부터 생성될 수도 있음
- 주어진 averaging latent codes
- encoding : data point 기존 학습된 (brown hair 이라는 벡터에서) 새로운 vector 를 추가할 수 있음 ( blond hair)
- realistic intermediate datapoint : 잠재 벡터 간 보간 및 디코딩 포인트는 현실적인 평균 데이터를 생성할 수 있음
대부분의 작업은 연속적인 데이터를 갖고 있음 (이미지와 같은) sequential data 를 모델링하는 것 두문 task
특히 악보와 같은 개별 token seq 의 경우 autoregressive decoder를 사용하여야 함
autoregression 이 더 효과적인 이유는 autoencoder 가 latent code 를 무시하기 때문임 (?)
짧은 문장들에서는 성공적인 생성을 보여주었지만 아주 긴 sequence 에 대해서는 어려웠음
긴 sequence 에 대한 modeling 문제 극복을 위해 계층적 순환 디코더가 있는 auto encoder 를 도입함
본 논문에서는 음표의 sequence 모델링에 초점을 맞추었음
대중음악은 특히
1. 한 곡의 음절 사이가 반복되고 변화되는 장기적 구조를 보임
2. 다중 음악
두가지 특성을 가지고 있음
2. Background
기본적으로 본 모델은 auto encoder 임
즉 입력을 정확하게 재구성하는 것이 목표
추가적으로 latent space interpolate 및 속성 벡터의 산술을 원하였기 때문에 vae 를 사용함
2.1 vae
auto encoder 는 input 에 대한 정보를 저차원의 latent code 로 압축하게 됨
모델이 데이터 셋의 중요한 변동 요인을 capture 하는 압축된 representations 를 생성하도록 한다
이 목표를 추구하기 위해 variational Auto encoder 는 latent code z 가 Prior p(z) 에 따라 분포된 random 변수라는
제약 조건을 둔다.
따라서 데이터 생성 모형은

다음과 같아진다. VAE 는 P(z|a) 를 근사하는 인코더 qx(z|x) 와 우도 p(x) 를 parameterize 하는 디코더 P seta(x|z) 로 구성됨
실제로 대략적인 후방 및 우도 분포는 각각 매개 변수 lambda 및 seta 를 가진 신경망에 의해 parametrize 되며
vae 프레임워크에 따라 ELBO 를 최대화하여 인코더에서의 근사 posterior 과 실제 posterior P(z|x) 사이의 KL 차이를 최소화 하여 후방 추론을 수행한다

위의 공식에서

와 KL 에 대한 expectation 이 취해짐 ELBO 를 통한 기울기를 계산하는 것은 z 를 얻는데 사용되는 sampling 작업 때문에
불가능함 따라서 p(z) 를 가우스 함수라고 가정하여

로 대체함으로써 이를 해결할 수 있음

2.1.1 B-VAE
VAE 에서 사용되는 ELBO 를 해석하는 방법은

2.1.1 B-vae and Free Bits
VAE 에서 ELBO 를 해석하는 한가지 방법은


두가지 용어를 고려하는 것이다
첫번째 E 는 정확한 재구성을 보장하기 위해 q (z|x) 의 z 샘플에 대해 p(x) 가 높음을 요구하는 것
두번째는 q (z|x) 가 p(z) 에서 latent code 를 샘플링하여 현실적인 데이터를 생성할 수 있도록 presense 에 근접하도록 장려함
B < 1 을 설정하면 모델이 compact 한 representation learning 보다 reconstruction quality 를 우선시 할 수 있음

이 임계값을 활용하는 것은 posterior 학습할 때에 사용되는 free bit 의 buget(?) 의 모델에 제공하는 것과 같음
수정된 objectives 는 likelihood 의 하한을 최적화 하지는 않지만 여전히 모델을 vae 라고 부름
2.1.2 Latent Space Manipulation
auto encoder 의 광범위한 목표는 데이터의 representation 을 배우는 것
latent space 를 사용하면 latent 변수의 변화를 통해 다른 결과 값을 얻을 수 있음
1. 현실의 데이터 포인트에 매핑되는 latent space 의 point 가 주어지면 근처의 latent space 포인트는
의미적으로 유사한 데이터 포인트에 매핑되어야 함
extrapolation 을 통해 latent space 에서 두 점을 연결하는 연속 곡선을 따라 있는 모든 점들이 데이터 공간에서 보간을 생성하는 일련의 data point 로 디코딩 될 수 있어야함
latent space 가 매끄럽고 현실의 데이터에 매핑되지 않는 부분 즉 구멍이 포함되지 않기를 요구함
2. latent space 가 데이터에서 의미있는 그룹을 분리하길 바람
이러한 요구사항은 vae 에 의해 충족되어야 함
test 데이터에서 likeli hood 및 kl 발산이 모두 충분히 작은 경우
잠재 공간의 점 사이를 보간하고 데이터 공간의 해당 point 가 의미 있는 방식으로 보간되는지 여부를 테스트한다.
만약 z1 과 z2 가 데이터 점 x1 과 x2 에 해당하는 잠재 벡터라면 계산을 통해 latent space 에서 선형 보간을 수행할 수 있음
정리 덜함
2.2 Recurrent VAEs
recurrent encoder 및 decoder 가 있는 모델에 대해 관심을 가짐
인코더인 q (z|x) 는 입력 시퀀스 x = {x1, x2, ..., xT} 를 처리하고 hidden state h1, h2 , ... , hT 의 시퀀스를 생성하는 반복 신경망임
latent code z 에 대한 분포의 매개 변수는 ht 의 함수로 설정됨 Decoder P (x|z) 는 sampling 된 latent vector z 를 사용하여 output sequence y = {y1, y2, : .y} 를 자동 회귀적으로 생성하는 decoder RNN 의 초기
본 모델은 입력 시퀀스 Yi = Xi, i {1, ..., T} 를 재구성하고 표준 VAE 에서와 같이 이전 p(z) 에 가까운 대략적인 후방 q (z|x) 를 학습하도록 훈련됨

sequence 의 자기 회귀 모델
반복적인 vae 에서 디코더는 그 자체로 데이터의 효과적인 모델을 생성할 수 있을만큼 충분히 강력하여 latent code 를 무시할 수 있음. latent code 를 무시하면 모델이 더이상 auto encoder 역할을 하지 않음에도 불구하고 ELBO 의 KL 발산항을 0으로 수렴하도록 할 수 있음
둘째로 모델은 전체 시퀀스를 단일 잠재 벡터로 압축해야함
짧은 시퀀스에 대해서는 효과를 봤지만 시퀀스의 길이가 증가함에 따라 실패하게 됨
이러한 문제를 해결하기 위해 계층적 RNN 을 사용하여 이러한 문제를 해결하는 latent variational auto encoder 를 제안함
'음악 생성' 카테고리의 다른 글
| [논문리뷰] - A Hierarchical Latent Vector Modelfor Learning Long-Term Structure in Music (Music Vae-2) (0) | 2023.01.15 |
|---|---|
| 음악 변형 및 합성 (MusicVAE 활용) (3) | 2022.11.29 |
| 음악 변형 및 합성 (vae) (0) | 2022.11.29 |
| [논문 리뷰] Multi-instrument Music Synthesis with Spectrogram Diffusion (0) | 2022.08.30 |