abstract
처음으로 음성 audio 에서 representation 을 학습한 뒤 전사된 음성에서 fine tuning 을 수행
wav2vec 2.0 은 hidden space 에서 audio input 을 마스킹하고 hidden layer 를 (양자화에 거쳐 정의된 대조 작업을 해결)
Librispeech 의 모든 레이블링된 데이터를 사용한 시험은 clean/기타 test set 에서 1.8/3.3 WER 를 달성함
라벨링 데이터 양을 1시간으로 줄이면 wav2vec 2.0 은 라벨링된 데이터를 100배 적게 사용하면서 100시간의 subset 에서 이전 성능을 능가함
레이블이 지정된 데이터를 10분만에 사용하고 레이블이 지정되지 않은 데이터를 53k 시간동안 사전 교육해도 여전히 4.8/8.2 WER 을 달성함
Introduction
self supervised learning -> 데이터 자체의 representation 을 잘 학습하기 위함임 ( 유아기 언어 습득과 유사 )
SSL unlabeld data 데이터 자체의 representation 학습 후에 labeld data 사용하여 최종적으로 원하는 task 수행 하는 fine-tuning 방법
-> transfer learning 의 방법과 다른것인가?...
원 발화 데이터로부터 적절한 representation 을 학습하는 SSL 프레임 워크를 제안
1. 발화 데이터를 multi-layered CNN 으로 인코딩
2. 해당 latnet reperesentation 을 마스킹함
3. 마스킹된 latent representation 을 transformer 에 넣어 contextualized representation 을 얻고 적절한 레이블 얻을 수 있도록 학습함
Model
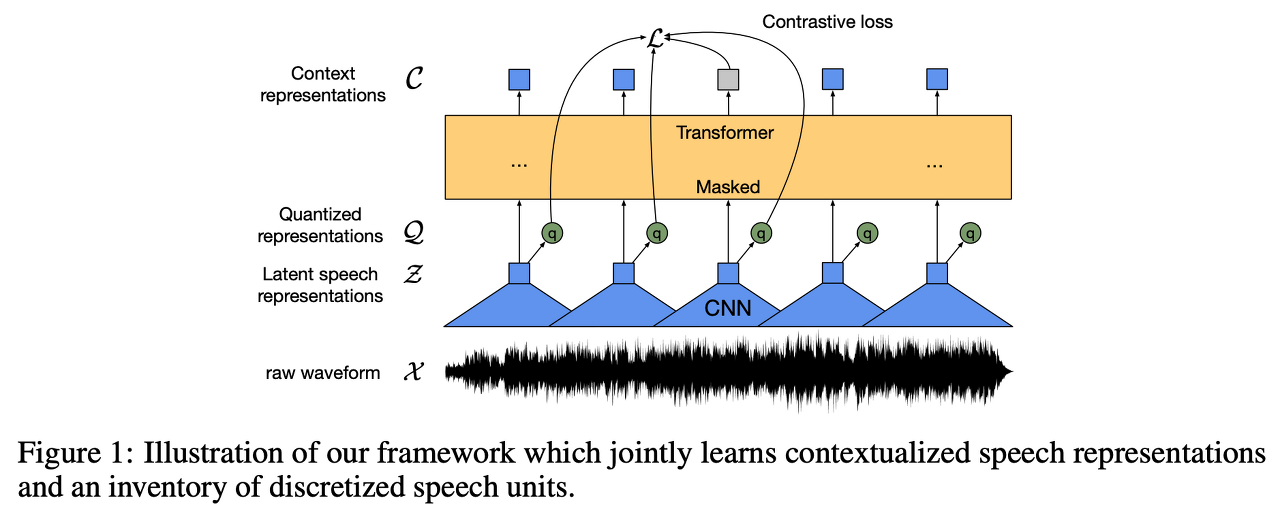
1. Multi-layer convolutional feature encoder f : X -> Z
- 원 발화 데이터 X 를 T step 의 latent representation z1 ... zT 로 임베딩
- layer normalization GELU 활용
- stride 가 time step T 를 결정
2. Transformer g : Z -> C
- representation c1 ... cT 로 임베딩
- positional embedding 에 convolutional layer 를 사용
- contextualized representation 산출
3. Quatization module Z -> Q
- self supervised training 을 위해 feature encoder f 를 통과한 z 에 product quantization 수행
- Product quantization PQ 의 서브벡터 code book 의 개수를 G 라고 하고 CNN 을 통과한 임베딩 벡터 R Vxd 라고 가정
- z 로 부터 크기가 R Vxd / G 인 G 개의 서브 벡터를 만들고 PQ 를 수행하여 각 서브벡터의 데이터를 클러스터링
각 서브 벡터에 PQ 를 수행할 때 서브 벡터의 entry 들이 code book 내에 정의된 centroid 중 가장 가까운 centroid 데이터로 변환 가장 가까운 centroid 를 찾는 과정은 gumbel softmax 를 통해 수행
- 클러스터링 이후 변환된 G 개의 데이터들을 concat 하여 크기가 d 인 벡터로 변환하고 단순 linear transformation d-> f 를 적용하여 q 를 얻음
- Quantization 을 거친 q 를 최종적으로 loss 계산에 이용해야하는데 code book 내의 가장 가까운 centroid 의 index 로 변환하는 과정이 discrete 하고 미분 불가능함.
gumbel softmax 는 이런 미분 불가능 작업을 역전파가 가능하게끔 미분 가능하게 만들어주는 activation func
- forward propagation 에서는 가장 가까운 centroid 를 찾는 argmax 함수를 이용 backward propagation 에서는 gumbel softmax 를 진행
Training
Masking
Bert 와 비슷한 방식으로 진행되는데 일부 time step 에 해당하는 부분의 Latent speech representation z 를 마스킹 하고 남은 부분으로 마스킹 하는 부분의 Quatized representation 을 유추하는 방식으로 사전 학습을 진행
Objective
L = Lm + a * Ld
여기서 Lm 은 contrastive loss
Ld 는 diversity loss
a 는 하이퍼 파라미터임
Loss 가 의미하는 바를 살펴보자
1. Contrastive Loss Lm
Lm 은 마스킹된 time step 은 Quatized representation 을 유추할 때에
Diversity Loss Ld
2. Diversity Loss Ld
Code book 의 entry 들이 균일하게 활용될수록 Loss 함수값이 감소하는 형태
Quantized representation 의 soft max 씌운것을 pg,v 로 정의하고 Ld 를 정의
Fine tuning
위 과정으로 pretrain 된 모델에 추가적인 Linear layer 를 context network 위에 붙이는 등 원하는 작업을 수행하도록 모델 구성
Experimental Setup
Results
Conclusion
'음성 합성' 카테고리의 다른 글
| vocoder 비교 - diffwave melgan vocgan (0) | 2023.01.01 |
|---|---|
| [논문리뷰] Cross-speaker Emotion Transfer (1) | 2022.11.24 |
| Tacotron 코드 리뷰 (0) | 2022.10.12 |