현재 실험에서는 Text2Mel 과정에 FastSpeech2를 적용하고, 보코더로는 MelGAN, VocGAN 그리고 DiffWave를 적용하여 한국어 TTS 시스템을 구성해 KSS 데이터셋으로 학습 수렴 속도 및 음성합성 품질을 실험했다. 실험 결과를 바탕으로 확산 모델 기반 보코더의 성능을 GAN 기반 보코더와 비교하여 분석했다. DiffWave는 MelGAN, VocGAN과 비교하여 MOS 성능이 유사하고 모델의 크기가 크지만, 수렴 속도 및 RTF(Real Time Factor)가 더 뛰어났다
텍스트-음성 변환(Text-to-Speech, TTS) 시스템은 임의의 텍스트를 입력으로 받아들여 해당 텍스트를 발음하는 사람의 음성신호를 합성한다. 고전적인 TTS 시스템은 텍스트 전처리, 구문 분석, 발음표기 변환, 경계 분석, 운율 조정, 음향 모델에 의한 음향 특징 생성, 합성음 생성 등 여러 모듈로 구성되어 있다. 그러나 딥러닝 기반 TTS 시스템은 텍스트에서 스펙트로그램을 생성하는 Text2Mel 과정과 스펙트로그램에서 음성신호를 합성하는 보코더로 구성되어 그 구조가 간단하다.
Text2Mel 과정은 텍스트에서 스펙트로그램을 생성하는 과정이다. 텍스트를 음소로 변환해 언어적 특징(linguistic feature)를 추출하여 음향 특징(acoustic feature)을 스펙트로그램 형식으로 생성한다. 대부분의 음성 생성 모델은 스펙트로그램의 주파수 단위를 mel-scale으로 재조정한 멜-스펙트로그램(mel-spectrogram)을 사용한다.
멜-스펙트로그램은 사람의 청각 기관이 고음보다 저음에서의 주파수 변화에 민감하다는 특징을 반영해 저음역대의 주파수를 더 세밀하게 표현한다. 하지만 주파수 성분의 위상(phase) 정보가 손실되기 때문에 원본 음성을 복구하기 위해서는 위상 정보를 예측하고 이를 바탕으로 원본 음성을 예측해야 한다.
보코더는 멜-스펙트로그램에 포함되지 않은 위상 정보를 예측해 원본 음성을 생성해낸다. 전통적인 방법으로는 Griffin-Lim과 같은 rule-based 알고리즘이 있지만, 원본 음성을 잘 복원해내지 못한다. 최근에는 심층 신경망(Deep Neural networks, DNN) 등의 통계 모델을 사용하여 예측 성능을 개선하는 기술이 제안되고 있다. 현재 실험에서는 심층 신경망을 사용한 보코더를 다룬다.
1. 실험 환경
실험에 사용한 음성은 전문 여성 성우 한 명이 한국어 사전 4권의 예문을 읽은 약 13,000문장, 약 16시간의 발화를 사용했다. 샘플링 주파수는 22,050Hz, 선형 PCM 16Bit 포맷으로 전처리했다. 데이터는 각 음성 파일의 경로와 전사 데이터로 구성되어 있다. 전체 13,000개 음성 파일 중 12,000개를 학습용 데이터, 500개를 검증용 데이터, 500개를 테스트용 데이터 사용했다. 모델 학습 및 합성음 생성 환경은 Ubuntu 20.0LTS, RAM 32GB, GPU는 Nvidia GTX 1080TI 11GB를 사용했다. 전처리에서는 원활한 학습을 위해 음성의 시작과 끝부분의 묵음을 제거했다. 음성신호의 최소와 최대 주파수를 각각 0Hz, 8,000Hz로 하여 80채널의 멜-스펙트로그램을 생성했다. Text2Mel으로는 FastSpeech2를 보코더를 학습에 사용한 것과 동일한 데이터로 1,000epoch 학습해 사용했다.
가) FastSpeech2
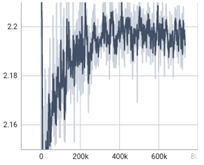
나) MelGAN
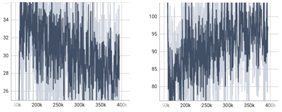
다) VocGAN
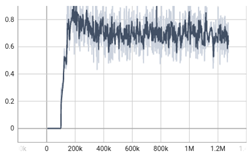
라) DiffWave
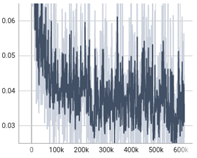
3. 실험 결과
학습된 모델의 크기를 비교하면 DiffWave의 크기가 GAN 기반의 두 모델보다 훨씬 작다. 음성 합성에 걸리는 시간 또한 DiffWave가 다른 두 모델에 비해 2배 정도 빠르다.
| MelGAN | VocGAN | DiffWave | |
| 모델 크기 | 243MB | 105MB | 31MB |
| 합성 시간 | 1.091s | 1.150s | 0.650s |
합성음의 품질에 대한 주관적인 평가를 위해 20대 5인이 10개 합성음을 각각 3번씩 청취하고 각 합성음에 1점에서 5점까지 점수를 부여하였다. 그 결과 MelGan 3.2 VocGan 3.4 diffWave 4.4로 diffWave의 MOS가 가장 높았으며 MelGan의 MOS가 가장 낮았다.
| MelGAN | VocGAN | DiffWave | |
| MOS | 3.4±0.49 | 3.0±0.00 | 4.4±0.49 |
MelGan과 VocGan은 합성음에 기계음이 섞여 있지만 DiffWave는 기계음이 대부분 제거되어 MOS가 상대적으로 높게 나온 것으로 보인다. 또한, 두 GAN 기반의 보코더는 특정 음소에서 합성음이 깨지는데 DiffWave는 비교적 자연스러운 음성을 합성했다.
본 실험에서는 diffusion과 GAN 기반의 보코더를 비교해 한국어 TTS 시스템의 설계에 참고 기준을 제공하는 것을 목표로 하였다. 최근 여러 딥러닝 분야에서 sota를 달성하고 있는 확산 모델이 적용된 DiffWave를 GAN 기반의 보코더들과 비교하고 그 성능을 실험으로 검증했다.
Text2Mel 모델은 FastSpeech2를 사용했고 보코더로는 MelGAN, VocGAN 그리고 DiffWave를 사용했다.
학습된 DiffWave는 MelGan과 VocGan 각각에 비해 모델의 크기는 12.7%, 29.5%에 불과했으며 합성 시간은 1.68배, 1.77배로 빨랐고 MOS 성능은 1점, 1.4점 높았다. Diffusion 기반 모델이 학습된 모델의 크기, 합성 속도 그리고 MOS 점수에서 GAN 기반의 모델들보다 성능이 우수함을 확인할 수 있었다.
실제 서비스에 적용되는 보코더는 저사양 하드웨어 환경에서도 높은 품질의 음성 합성을 빠른 속도로 처리할 수 있어야 한다. 실험 결과, DiffWave는 해당 요구 조건에 GAN 기반 모델보다 적합하다.
후속 연구로 HifiGAN, WaveGlow의 구현과 성능 검증을 추가로 진행할 계획이다.
'음성 합성' 카테고리의 다른 글
| [논문리뷰] Cross-speaker Emotion Transfer (1) | 2022.11.24 |
|---|---|
| Tacotron 코드 리뷰 (0) | 2022.10.12 |
| [논문리뷰]-wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations (0) | 2022.09.17 |