1. introduction
- 최근 연구 분야 : 자연스러운 음성 합성 및 고품질 음성 생성
- 본 논문의 목적 : 자연스러움을 더욱 향상시키기 위한 운율, 감정과 같은 텍스트 및
더 많은 정보들을 다룰 수 있도록 하는 것 (prosody)
- semi supervised learning 을 제안한 이유
지도 학습 : annotation 에 크게 의존하는 경향 (일반화 성능의 부족 -> 상업적 생산에 비실용적)
비지도 학습(encoder-decoder architecture) : 모델의 해석력, 제어 가능성의 부족
준지도 학습 : 학습된 representation의 해석력을 증가
- 제안 : semi-supervised cross-entropy loss 를 통해 style token 의 가중치를 one hot vector 로 전환
5% 의 감독 데이터가 있는 semi-GST 사용
(스타일 토큰 방법에서 5% 의 감독데이터를 통해 예측된 y 에 대해 스타일 토큰마다의 가중치를 변화하며 모델의 해석력을 검증할 수 있음)
- 문제 : annotation 이 주어지지 않으므로 감정 인식 및 발음 안정성이 보장되어야하고 음색 유사성이 유지되어야함
multi reference tactron2 는 여러개의 reference encoder 들을 사용하여 독립적인 화자와 스타일 representation 을 학습하려 시도하였음 (해석력 증가)
본 논문은 emotion annotation 없이 다감성 말뭉치를 가진 데이터를 통해 target 화자로 감정을 전달하는 것을 목표로 함
감정 인식 및 발음 안정성이 보장을 위해 제어 가능 Tacotron 을 베이스로 variational residual encoder 를 GST 모듈로 대체한 모델을 제안함
1) controllable 한 감정 전달을 위해 GST 및 semi-supervised 를 사용
2) 화자간 감정 전달 작업에 speaker condition layer normalization[SCLN] 을 사용함
기존의 연구는 speaker 와 감정 임베딩을 명시적으로 제한하였던 반면 본 논문에서는 SCLN 블록을 통해 화자 임베딩을 학습하고 GST 및 semi-supervised 를 통해 감정 임베딩을 학습하게 됨
2. Proposed Method
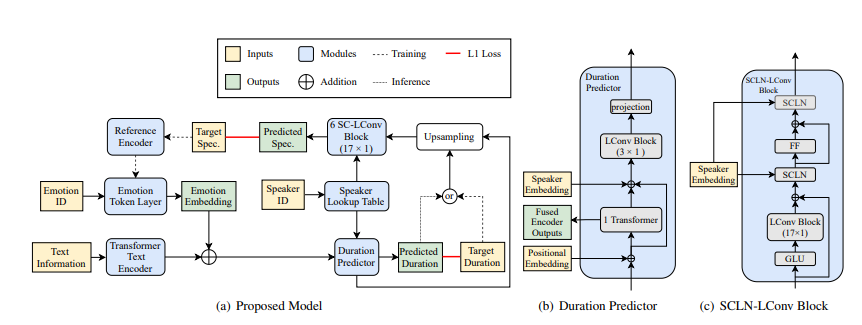
주로 Transformer 기반의 텍스트 인코더, Transformer 기반 Duration Predictor, upsampling block, spectrogram decoder stack, reference encder, style token layer 로 구성됨
2.1 Duration Predictor
emotion embedding 에 의해 추가된 encoder output 을 입력으로하여 음소 duration 을 출력함
duration predictor 학습을 위해 HMM(hidden markov chain) 을 사용함
(encoder 단에서 aligner 에서의 아웃풋으로 다운샘플링된것을 얻고 디코더를 통해 업샘플링하여 오디오의 해상도를 높임)
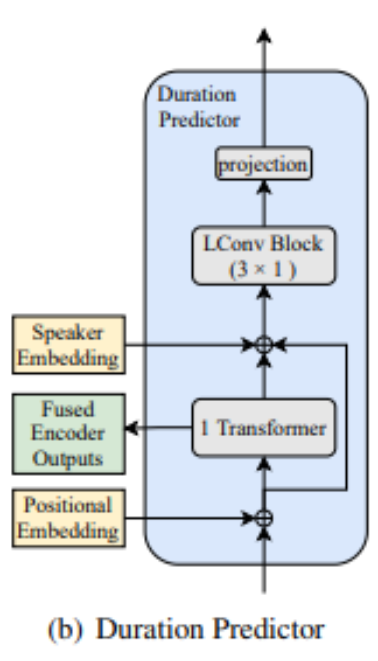
Transformer 블록의 출력은 upsampling에 사용됨 upsampling된 output 을 LConv 의 입력으로 받음
speaker 및 emotion 관련 duration 은 LConv 블록과 projection layer 에 의해 예측됨
2.2 SCLN-LConv Block
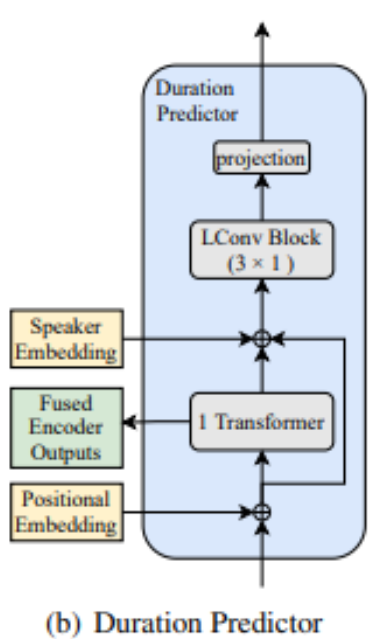
spectrogram decoder 는 6개의 SCLN-LConv 블록으로 구성됨
SCLN 모듈은 스피커 임베딩을 입력으로 취하고 layer norm 에 대해 scale 및 prameter 를 예측함
2.3 Emotion Token Layer and Semi-Supervised Training
emotion embedding 을 통해 감정 속성을 모델링함.
target 이 되는 mel spectrogram 이 reference encoder 의 input 으로 사용됨
refrence encoder 는 input spectrogram 을 reference embedding(고정 길이 벡터) 로 인코딩함
single head self attention (입력된 값들 사이의 연관성 파악) 감정 임베딩은 emotion token 의 가중치 합에 의해 생성됨
token weight 과 one hot encoding된 감정 ID 사이에 감정 분류를 위한 loss 를 추가하여 trained 된 token 이 감정과 일대일 대응을 갖도록 함
target speaker 에는 emotion 에 관한 annotation 이 없어 모든 emotion 을 중립적으로 간주하는 대신
emotion classification loss 를 통해 준지도 학습 문제로 정의함
각 음성에 포함된 감정을 부드럽게 결정함
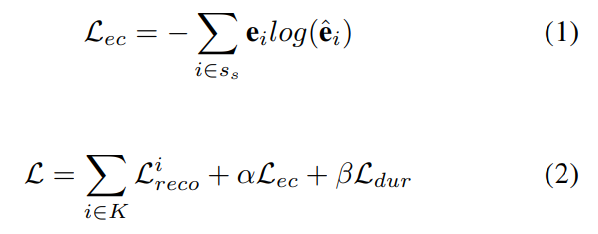
L(i)reco 는 i 번째 decoder 의 reconstruction loss
K 는 decoder 의 개수
L dur 는 duration loss
L ec 는 emotion classification loss
S s 는 speaker 를 나타내고
a 는 emotion classification loss 가중치, b 는 duration loss 가중치
3.1 Experimental Setup
두명의 남성 화자와 중국어 음성 데이터 베이스 두개가 실험에 사용됨
7가지 감정 주석이 있는 다중 감정 음성 데이터베이스와 오디오북 데이터베이스를 사용
baseline : paried-unparied 훈련 전략 및 adversarial cycle consistency 를 사용하는 병렬 타코트론 기반 모델
reference encoder에 의해 생성된 감정 embedding 과 speaker embedding 은 encoder 출력과 연결
M1 : 디코더 LConv 블록에서 SCLN 모듈을 제거하고 speaker embedding 이 인코더 출력에 추가됨
M2 : 훈련 단계에서 emotion classification loss 를 제거하는 모델 (멀티 헤드 어텐션을 사용)
- 음색 유사성 : 대상 화자의 합성된 음성과 원본 화자와 대상 화자의 녹음 2개가 각각 제공됨
- 안정성 비교 : 서로 다른 모델의 합성된 음성이 주어졌을때 참가자에게 누락된 단어, 말하는 속도 문제, 흐릿한 음성 및 발음 결함과 같은 안정성 문제가 있는지 피드백을 제공
- 감정 인식 : 음성은 동일한 감정 레이블과 텍스트를 사용하여 두 모델에서 합성됨
감정 레이블의 설명에 더 가깝게 인식되는 발언을 결정
3.2.1 Comparison with baseline
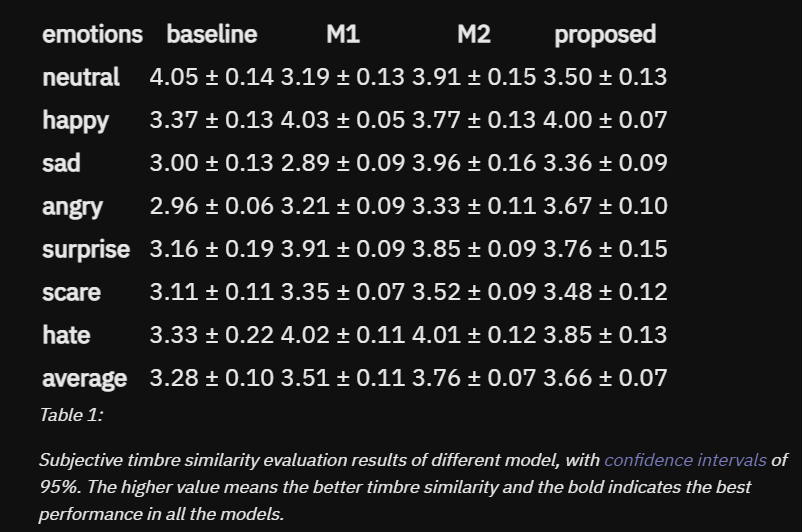
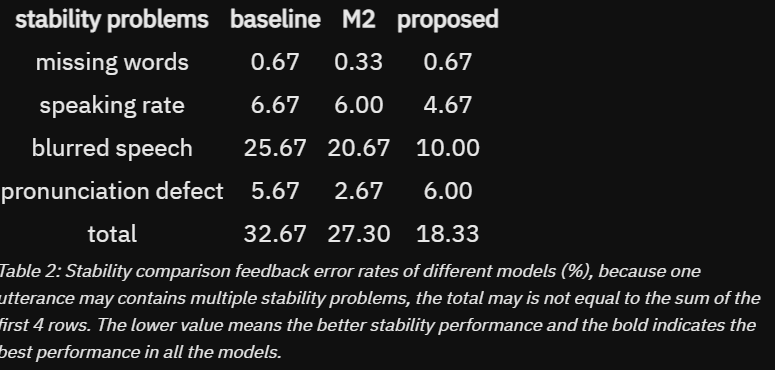
3.2.2 Ablation Evaluations
SCLN-LConv 과 semi-supervised 전략의 효과를 입증
1. proposed / M1(SCLN-LConv 제거)
M1 에 비해 전체적 음색 유사도 점수가 0.15 향상됨 (슬픔 화남에서 특히 좋은 성능을 보임)
2. proposed / M2(emotion classification loss)
M2 가 음색 유사도에서는 조금 더 우월했지만 미미한 차이였고 안정성 측면에서 proposed 가 9% 정도 더 높았다
산업에서 적용되는 것을 생각해 보았을 때에 실시간 TTS 시스템은 안정성이 더 중요하다는 점을 고려하여
제안한 방법을 최종 구성으로 선택함
4. Conclusion
semi-supervised training 과 SCLN 기반 감정 전달 방법의 제안
화자간 감정 전달 중 화자의 특성을 보존하기 위해 화자 상태 계층 정규화 모듈이 구현됨
상대적으로 높은 안정성과 음색 유사성을 유지하면서 감정 전달의 목표를 달성할 수 있음
- 기타
annotation : input 에 추가적으로 wav text label 이외에 감정 화자성별 등이 들어가게 됨
about Styler : 예를 들어 FastSpeech 2[Ren21a]에서는 duration, pitch, energy 정보를 예측하는 부분이 추가되었음. FastPitch[Łancucki21]에도 추가적으로 세세하게 pitch를 조정할 수 있음. 이를 개선한 FastPitchFormant[Bak21]에서는 source-filter모델을 acoustic model에 적용하여 더욱 pitch를 robust하게 조절할 수 있는 방법을 제안함. Styler[Lee21c]에서는 pitch, duration, energy에다가 noise 정보까지 활용하여 더욱 noise에 robust하게 스타일을 조절할 수 있는 방법을 소개함.
'음성 합성' 카테고리의 다른 글
| vocoder 비교 - diffwave melgan vocgan (0) | 2023.01.01 |
|---|---|
| Tacotron 코드 리뷰 (0) | 2022.10.12 |
| [논문리뷰]-wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations (0) | 2022.09.17 |